Social Media
Facebook details AI advances in catching misinformation and hate speech
Facebook’s battle against misinformation will never be over at this rate, but that doesn’t mean the company has given up. On the contrary it is only by dint of constant improvement to its automated systems that it is able to keep itself even remotely free of hate speech and misinformation. CTO Mike Schroepfer touted the latest of those improvements today in a series of posts.
The changes are to the AI-adjacent systems the social network uses to nip the likes of spam, misleading news items and racial slurs in bud — that is to say before anyone, including Facebook’s own content moderators, sees those items.
One improvement is in the language analysis systems Facebook employs to detect things like hate speech. This is one area, Schroepfer explained, where the company has to be extremely careful. False positives in the ad space (like that something seems scammy) are low-risk, but false positives taking down posts because they’re mistaken for hate speech can be serious issues. So it’s important to be very confident when making that determination.
Unfortunately hate speech and adjacent content can be really subtle. Even something that seems indisputably racist can be inverted or subverted by a single word. Creating machine learning systems that reflect the complexity and variety of language is a task that requires exponentially increasing amounts of computing resources.
Linformer (“linear”+”transformer”) is the new tool Facebook created to manage the ballooning resource cost of scanning billions of posts a day. It approximates the central attention mechanism of transformer-based language models rather than calculating it exactly, but with few trade-offs in performance. (If you understood all that, I congratulate you.)
That translates to better language understanding but only marginally higher computation costs, meaning they don’t have to, say, use a worse model for a first wave and then only run the expensive model on suspicious items.
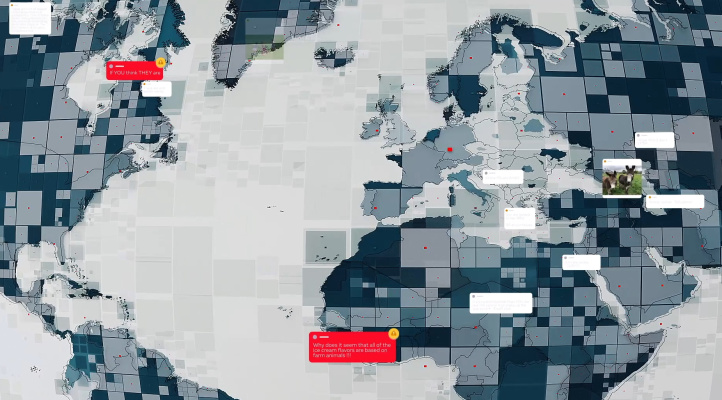
The company’s researchers are also working on the slightly less well-shaped problem of understanding the interaction of text, images and text in images. Fake screenshots of TV and websites, memes and other things often found in posts are amazingly difficult for computers to understand but are a huge source of information. What’s more, a single changed word can completely invert their meaning while almost all the visual details remain the same.
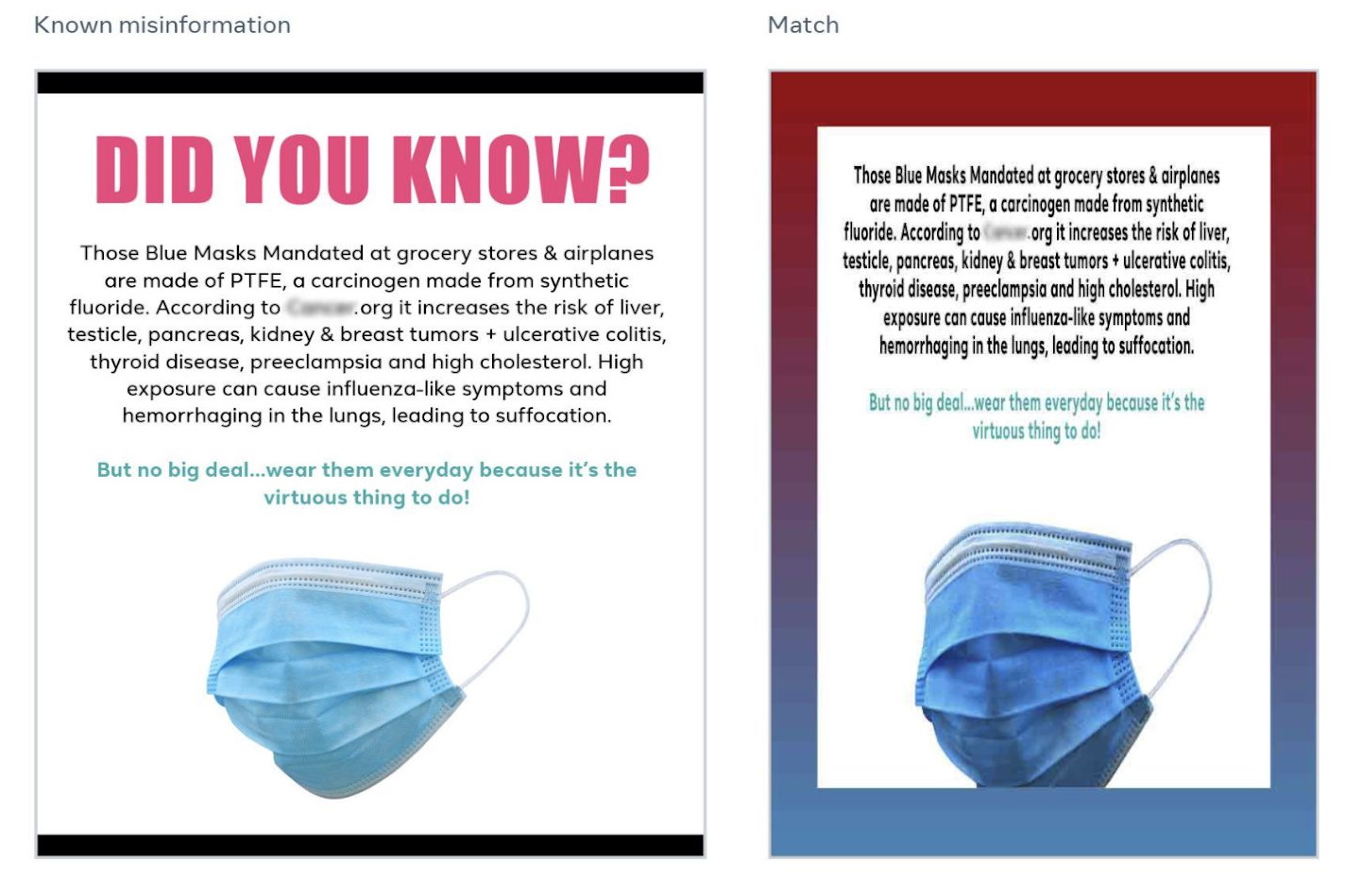
An example of two instances of the same misinformation with slightly different visual appearance. Aware of the left one, the system caught the right one. Image Credits: Facebook
Facebook is getting better at catching these in their infinite variety, Schroepfer said. It’s still very difficult, he said, but they’ve made huge strides in catching, for instance, COVID-19 misinformation images like fake news reports that masks cause cancer, even when the people posting them manipulate and change their look.
Deploying and maintaining these models is also complex, necessitating a constant dance of offline prototyping, deployment, online testing and bringing that feedback to a new prototype. The Reinforcement Integrity Optimizer takes a new approach, monitoring the effectiveness of new models on live content, relaying that information to the training system constantly rather than in, say, weekly reports.
Determining whether Facebook can be said to be successful is not easy. On one hand, the statistics they publish paint a rosy picture of increasing proportions of hate speech and misinformation taken down, with millions more pieces of hate speech, violent images and child exploitation content removed versus last quarter.
I asked Schroepfer how Facebook can track or express their success or failure more accurately, since numbers increases might be due to either improved mechanisms for removal or simply larger volumes of that content being taken down at the same rate.
“The baseline changes all the time, so you have to look at all these metrics together. Our north star in the long run is prevalence,” he explained, referring to the actual frequency of users encountering a given type of content rather than whether it was preemptively removed or some such. “If I take down a thousand pieces of content that people were never going to see anyway, it doesn’t matter. If I take down the one piece of content that was about to go viral, that’s a massive success.”
Facebook now includes hate speech prevalence in its quarterly “community standards enforcement report,” and it defines it as follows:
Prevalence estimates the percentage of times people see violating content on our platform. We calculate hate speech prevalence by selecting a sample of content seen on Facebook and then labeling how much of it violates our hate speech policies. Because hate speech depends on language and cultural context, we send these representative samples to reviewers across different languages and regions.
And for its first measure of this new statistic:
From July 2020 to September 2020 was 0.10% to 0.11%. In other words, out of every 10,000 views of content on Facebook, 10 to 11 of them included hate speech.
If this number is not misleading, it implies that one in a thousand pieces of content online right now on Facebook qualifies as hate speech. That seems rather high. (I’ve asked Facebook for a bit more clarity on this number.)
One must question the completeness of these estimates as well — reports from war-torn areas like Ethiopia suggest that they are rife with hate speech that is inadequately detected, reported and taken down. And of course the eruption of white supremacist and nationalist militia content and groups on Facebook has been well-documented.
Schroepfer emphasized that his role is very squarely in the “implementation” side of things and that questions of policy, staffing and other important parts of the social network’s vast operations are more or less out of his jurisdiction. Frankly that’s a bit of a disappointing punt by the CTO of one of the most powerful companies in the world, who seems to take these issues seriously. But one also wonders whether, had he and his teams not been so assiduous in pursuing technical remedies like the above, Facebook might have been completely snowed under with hate and fakery rather than being simply unavoidably shot through with it.


Greatest films by women creators on Netflix

Beyoncé’s Christmas halftime show on Netflix: What to know about the NFL event

2024: A year of digital organizing from Palestine to X

Should you buy the 2024 Kindle Paperwhite Signature Edition?

Mars is littered with junk. Historians want to save it.

‘The Wild Robot’ and ‘Flow’ are quietly revolutionary climate change films

Review: Is the $499 Bose Smart Soundbar worth it?

CES 2025 preview: What to expect

‘The Room Next Door’ review: Tilda Swinton and Julianne Moore are magnificent

Polyamorous influencer breakups: What happens when hypervisible relationships end

Black Friday Ninja deals: Ninja Slushi in stock, plus the Creami and air fryers on sale

Intel’s 20-year-old AI ethicist, who graduated high school at 11, discusses the future

Yoto Player review: This screen-free speaker keeps kids entertained and engaged

‘A Complete Unknown’ review: Timothée Chalamet infuriates as Bob Dylan

Bluesky can learn from Twitter’s early mistakes

Greatest Cyber Monday streaming deals 2024: Save up to 90% on Hulu, Peacock

HP Omen 17 review: This gaming laptop stays cool under pressure
Greatest post-Cyber Monday deals 2024: Shop Amazon, Greatest Buy, Target, more

Apple Black Friday deals 2024: Amazon has record-low prices

Amazon Black Friday laptop deals: Shop record lows on M3 MacBook Air, Microsoft Surface Laptop 7
Greatest films by women creators on Netflix
Beyoncé’s Christmas halftime show on Netflix: What to know about the NFL event
2024: A year of digital organizing from Palestine to X
Should you buy the 2024 Kindle Paperwhite Signature Edition?
Mars is littered with junk. Historians want to save it.
‘The Wild Robot’ and ‘Flow’ are quietly revolutionary climate change films
Review: Is the $499 Bose Smart Soundbar worth it?
CES 2025 preview: What to expect
‘The Room Next Door’ review: Tilda Swinton and Julianne Moore are magnificent
Polyamorous influencer breakups: What happens when hypervisible relationships end
-

 Entertainment6 days ago
Entertainment6 days agoOpenAI’s plan to make ChatGPT the ‘everything app’ has never been more clear
-

 Entertainment5 days ago
Entertainment5 days ago‘The Last Showgirl’ review: Pamela Anderson leads a shattering ensemble as an aging burlesque entertainer
-

 Entertainment6 days ago
Entertainment6 days agoHow to watch NFL Christmas Gameday and Beyoncé halftime
-
 Entertainment5 days ago
Entertainment5 days agoPolyamorous influencer breakups: What happens when hypervisible relationships end
-
 Entertainment4 days ago
Entertainment4 days ago‘The Room Next Door’ review: Tilda Swinton and Julianne Moore are magnificent
-
 Entertainment3 days ago
Entertainment3 days ago‘The Wild Robot’ and ‘Flow’ are quietly revolutionary climate change films
-
 Entertainment4 days ago
Entertainment4 days agoCES 2025 preview: What to expect
-
 Entertainment3 days ago
Entertainment3 days agoMars is littered with junk. Historians want to save it.