Business
Implement differential privacy to power up data sharing and cooperation

Traditionally, companies have relied upon data masking, sometimes called de-identification, to protect data privacy. The basic idea is to remove all personally identifiable information (PII) from each record. However, a number of high-profile incidents have shown that even supposedly de-identified data can leak consumer privacy.
In 1996, an MIT researcher identified the then-governor of Massachusetts’ health records in a supposedly masked dataset by matching health records with public voter registration data. In 2006, UT Austin researchers re-identifed films watched by thousands of individuals in a supposedly anonymous dataset that Netflix had made public by combining it with data from IMDB.
In a 2022 Nature article, researchers used AI to fingerprint and re-identify more than half of the mobile phone records in a supposedly anonymous dataset. These examples all highlight how “side” information can be leveraged by attackers to re-identify supposedly masked data.
These failures led to differential privacy. Instead of sharing data, companies would share data processing results combined with random noise. The noise level is set so that the output does not tell a would-be attacker anything statistically significant about a target: The same output could have come from a database with the target or from the exact same database but without the target. The shared data processing results do not disclose information about anybody, hence preserving privacy for everybody.
To implement differential privacy, one should not start from scratch, as any implementation mistake could be catastrophic for the privacy guarantees.
Operationalizing differential privacy was a significant challenge in the early days. The first applications were primarily the provenance of organizations with large data science and engineering teams like Apple, Google or Microsoft. As the technology becomes more mature and its cost decreases, how can all organizations with modern data infrastructures leverage differential privacy in real-life applications?
Differential privacy applies to both aggregates and row-level data
When the analyst cannot access the data, it is common to use differential privacy to produce differentially private aggregates. The sensitive data is accessible through an API that only outputs privacy-preserving noisy results. This API may perform aggregations on the whole dataset, from simple SQL queries to complex machine learning training tasks.
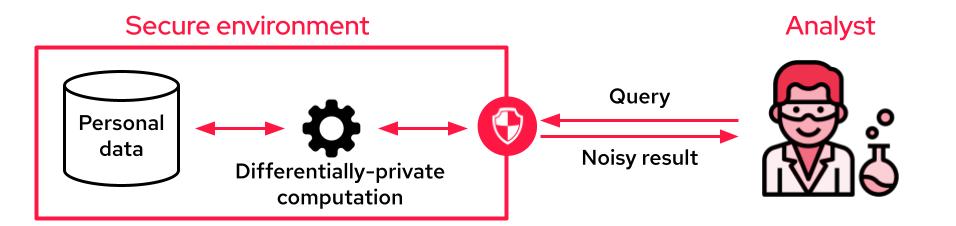
A typical setup for leveraging personal data with differential privacy guarantees. Image Credits: Sarus
One of the disadvantages of this setup is that, unlike data masking techniques, analysts no longer see individual records to “get a feel for the data.” One way to mitigate this limitation is to provide differentially private synthetic data where the data owner produces fake data that mimics the statistical properties of the original dataset.


Why women behaving badly are dominating our screens

‘Spellbound’ review: Netflix’s animated adventure finds its magic right at the end

2024 Black Friday ads: Greatest deals from Target, Greatest Buy, Walmart, Kohls, and more

Greatest Amazon Black Friday deals: Early savings on Fire TVs, robot vacuums, and MacBooks

A24 is selling chocolate now. But what would their films actually taste like?

New teen video-viewing guidelines: What you should know

‘Wicked’ review: Ariana Grande and Cynthia Erivo aspire to movie musical magic

How to watch ‘Smile 2’ at home: When is it streaming?

Black Friday 2024: The greatest early deals in Australia – live now

‘Dune: Prophecy’ review: The Bene Gesserit shine in this sci-fi showstopper

‘Here’ review: Robert Zemeckis, Tom Hanks, and Robin Wright reunite

The 34 greatest Australian horror films (and where to watch them)

Menendez brothers case reignites online: The questions that keep resurfacing

How to watch the 2024-2025 NBA season without cable: The greatest streaming deals

Election 2024: The truth about voting machine security

Halloween 2024: Weekend debates, obscure memes, and a legacy of racism

‘Only Murders in the Building’ Season 4 ending explained: Who killed Sazz and why?

‘Dragon Age: The Veilguard’ review: BioWare made a good game again

‘Wallace and Gromit: Vengeance Most Fowl’ review: A delightful romp with an anti-AI streak

Review: I tested the new GoPro Hero 13 Black by land and sea
Why women behaving badly are dominating our screens
‘Spellbound’ review: Netflix’s animated adventure finds its magic right at the end
2024 Black Friday ads: Greatest deals from Target, Greatest Buy, Walmart, Kohls, and more
Greatest Amazon Black Friday deals: Early savings on Fire TVs, robot vacuums, and MacBooks
A24 is selling chocolate now. But what would their films actually taste like?
New teen video-viewing guidelines: What you should know
‘Wicked’ review: Ariana Grande and Cynthia Erivo aspire to movie musical magic
How to watch ‘Smile 2’ at home: When is it streaming?
Black Friday 2024: The greatest early deals in Australia – live now
‘Dune: Prophecy’ review: The Bene Gesserit shine in this sci-fi showstopper
-

 Entertainment7 days ago
Entertainment7 days agoEarth’s mini moon could be a chunk of the big moon, scientists say
-

 Entertainment7 days ago
Entertainment7 days agoThe space station is leaking. Why it hasn’t imperiled the mission.
-
 Entertainment6 days ago
Entertainment6 days ago‘Dune: Prophecy’ review: The Bene Gesserit shine in this sci-fi showstopper
-
 Entertainment5 days ago
Entertainment5 days agoBlack Friday 2024: The greatest early deals in Australia – live now
-
 Entertainment4 days ago
Entertainment4 days agoHow to watch ‘Smile 2’ at home: When is it streaming?
-
 Entertainment3 days ago
Entertainment3 days ago‘Wicked’ review: Ariana Grande and Cynthia Erivo aspire to movie musical magic
-
 Entertainment2 days ago
Entertainment2 days agoA24 is selling chocolate now. But what would their films actually taste like?
-
 Entertainment3 days ago
Entertainment3 days agoNew teen video-viewing guidelines: What you should know